Spurred on by the explosion of interest in the Internet of Things, there’s been an explosion of interest in embedded systems. Because of this, Embedded.com is running excerpts from Embedded Computing for High Performance, a recent book by João Cardoso, José Gabriel Coutinho, and Pedro Diniz. In this and my next few posts, I’ll be briefly summarizing these excerpts (and encouraging all readers to read the articles in their entirety, as there’s a lot to learn in them and the writing is clear and straightforward). The first two articles focus on architecture: target architectures and multiprocessor and multicore architectures.
Target architectures
The authors acknowledge right up front something that those of us at Critical Link have been experiencing first hand throughout our history:
Embedded systems are very diverse and can be organized in a myriad of ways. They can combine microprocessors and/or microcontrollers with other computing devices, such as application-specific processors (ASIPs), digital-signal processors (DSPs), and reconfigurable devices (e.g., FPGAs [1,2] and coarse-grained reconfigurable arrays—CGRAs—like TRIPS [3]), often in the form of a System-on-a-Chip (SoC).
Here’s their diagram of a standard single CPU architecture. (Looks pretty familiar!)
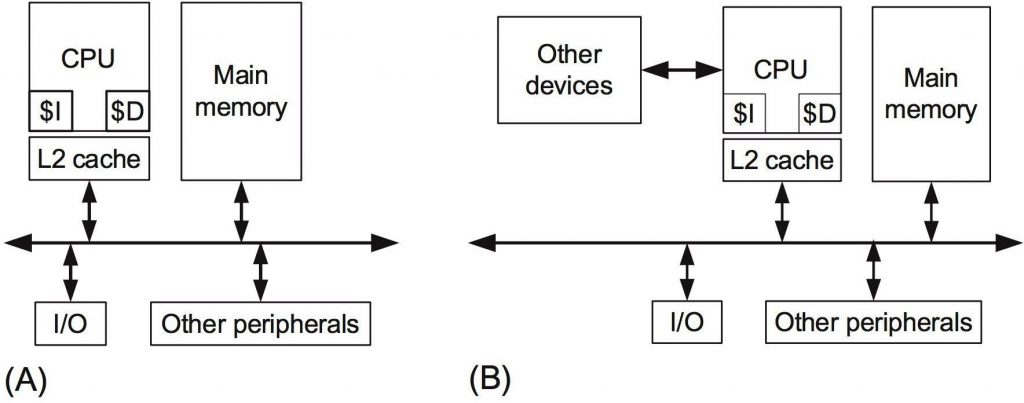
In their article, the authors take a look at a decades-long history of how performance improvements have come about, and discuss the tricks of the trade (code optimization, parallelizing sections of code) that engineers deploy to meet requirements.
They then address extending simple embedded systems like the one depicted above “by connecting the host CPU to coprocessors acting as hardware accelerators,” such as an FPGA and network coprocessors.
Depending on the complexity of the hardware accelerator and how it is connected to the CPU (e.g., tightly or loosely coupled), the hardware accelerator may include local memories (on-chip and/or external, but directly connected to the hardware accelerator). The presence of local memories, tightly coupled with the accelerator, allows local data and intermediate results to be stored, which is an important architectural feature for supporting data-intensive applications.
They then offer the reminder that hardware accelerators come with overhead: the cost of data movement between the accelerator and the host processor, so they offer different approaches with less communications overhead.
Multiprocessor and multicore architectures
Modern microprocessors contain a number of processing cores, each (typically) with “its own instruction and data memories (L1 caches) and all cores share a second level (L2) on-chip cache.” Here’s the authors’ diagram of a standard multicore (quad-core CPU) architecture. (Looks pretty familiar!)
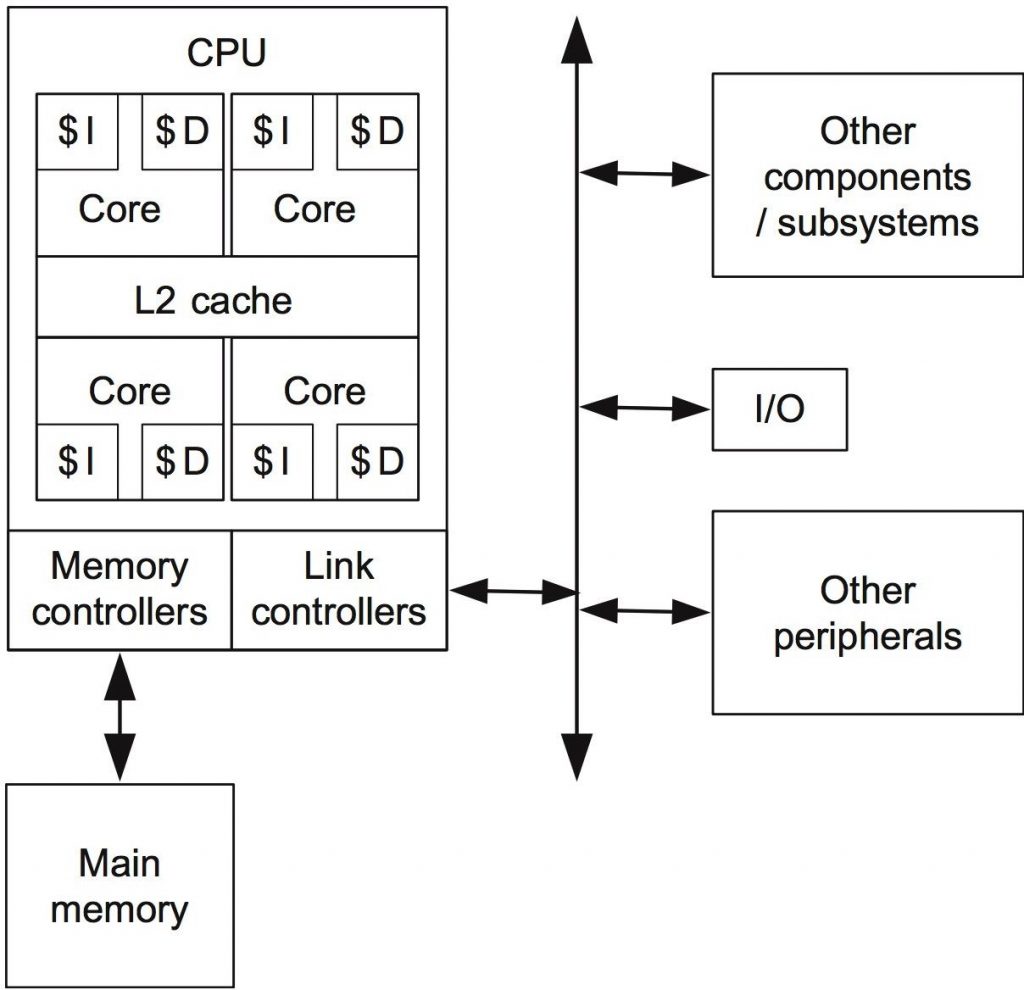
In the article on multiprocessor/multicore, the authors also talk about platforms that extend commodity CPUs with FPGA-based hardware.
I’ve just skimmed the surface here, but wanted to give a flavor on the types of information provided in these articles. Admittedly, it’s all textbook stuff, but if you’re interested in high performance embedded systems (and if you’re reading this post, you probably are) you may want to go over to embedded.com and read the articles through in their entirety.
In my next post, I’ll be summarizing the excerpts on core-based enhancements and hardware accelerators, but feel free to jump ahead and take a look at the full excerpts.